LA 挑战赛:添加系统调用异常支持
异常和中断
软硬协同
在 CPU (以 riscv 为例)上运行的 OS 上的应用程序(有点绕)可以发起 syscall,也就是系统调用。
当用户程序调用系统调用的时候(比如 write调用 ),实际上,走到了这里(大致描述):
1 | |
首先,将系统调用号放到 a7,接着执行 ecall 指令,进入到 trap_vector,在这里进行上下文切换、特权等级转换、设置一些 csr 之后,进入到了 trap_handler 中,OS 根据 mcause 判断是否是 syscall,如果是就执行相应的 syscall。
上面是一个大致的 syscall 指令流程。
可以看到,想要安全、有组织地执行一些代码,软件和硬件必须协同工作。软件本质上就是一系列指令序列,其中穿插了一些关键指令。这些关键指令为接下来的指令序列执行提供了前提条件。但如果是裸机系统,则完全可以移除 csr。
上面说到了硬件,实际上当把很复杂的行为解耦成一条条复杂度可以得到控制的特权指令,就是现在 ISA 中的做法。
这样,当我需要硬件变成我想要的状态时,我只需要执行几条正交的特权指令就行了。比如这个 trap_vector:
1 | |
这就是软硬协同的典型的例子。
更一般的,异常和中断事实上,都会进入同一个 trap_vector 之后,在进入到 trap_handler 中,从这里评价就是,它们都是同一个东西。
要在 CPU 中实现异常和中断,就是要按照手册实现一些关于 csr 的硬件功能,并且这些功能可以被特权指令触发。以下,将异常和中断统称为异常。
异常开始阶段
上面已经谈到了,syscall 作为一种典型的异常,它执行到特权指令 syscall 时(loongarch 中 就是 syscall 指令),硬件应该做什么呢?
首先应该保存 syscall 指令的 PC 吧(保存所有异常指令的 PC 到 csr_era 中),同时处理器应该处于高特权等级,接着跳转到 trap_vector 中,也就是所说的异常处理程序入口(实际上还做了其他事情,详见手册)。
异常处理的返回阶段
异常处理程序完成处理后,就可以返回了(给 PC+4 与否就看具体的情况了)。loongarch 使用 ertn 指令返回,这指令本身也是特权指令,功能是恢复特权等级、恢复中断。
精准异常
精准异常的概念就是,当执行到某个指令时,比如:
1 | |
当执行到 syscall 指令时,那就执行 syscall 的部分,执行完了之后再回到 syscall 之后,继续执行后面的指令,就好像 syscall 或者其它异常就没有执行过一样。这就是精准异常。
CSR(控制状态寄存器)
要能执行 syscall 以及时钟中断、break 等,相关的寄存器有:CRMD、PRMD、ECFG、
ESTAT、ERA、BADV、EENTRY、SAVE0~3、TID、TCFG、TVAL、TICLR。
异常判定
硬件中断的源头来自处理器核外部,可以认为每个处理器核都有 8 个中断输入引脚,设备或中断控制器将高电平有效的中断信号连接到这 8 个输入引脚上,而处理器核内部 ESTAT 控制状态寄存器 IS(Interrupt State)域的 9..2 这 8 位(RTL 上对应 8 个触发器)则直接对中断输入引脚的信号采样。
软件中断顾名思义是由软件来设置的,通过 CSR 写指令对 ESTAT 状态控制寄存器 IS 域的 1..0 这两位写 1 或写 0 就可以完成两个软件中断的置起和撤销。定时器中断的状态记录在 ESTAT 控制状态寄存器 IS 域的第 11 位。
中断的使能情况分两个层次:低层次是与各中断一一对应的局部中断使能,通过 ECFG 控制寄存器的 LIE(Local Interrupt Enable)域的 11 和 9..0 位来控制;高层次是全局中断使能,通过 CRMD 控制状态寄存器的 IE(Interrupt Enable)位来控制。
异常产生
取指地址错异常
检测 PC 最低两位就行。
地址非对齐异常
如果访存指令未自然对齐,那么就会触发这个异常。
指令不存在异常
检测所有的指令类型或,如果为 0,则触发异常。
系统调用和断点异常
检测 syscall、break 指令。
中断异常检测
这是重点,前面所有的异常都是由于指令本身引起的,而中断是由于外部事件导致的,它与指令之间并无直接对应关系。
但是由于中断是一种特殊的异常,我们希望用异常的处理流程来自然地处理中断,因此可以想到将异步的中断事件动态地标记在某一条指令上,被标记的指令随后就被赋予了中断这种异常,那么随后的处理就和其他异常非常类似了。
那么,将中断标记挂在哪一条哪一条指令上呢?我们统一处理,都挂在 IDU 上,当然,也可以挂在其它阶段。
精确异常的实现
参考 CPU 设计实战,可以将异常信息挂在指令上,每一个阶段都可以产生异常,但是只有在 WBU 阶段才会真正响应这些异常。
当 WBU 检测到异常时,需要给上游所有的部件发射一个信号,也就是 excp_flush 信号,这个信号通过组合电路输出。
这个信号会使得之前的所有指令缓存都被清空。这里有一个非常隐晦的问题,那就是什么是清空。
CPU 处理异常,本质上就是跳转到一个地址,并且引发异常的指令后面的指令不能有任何执行效果。还有,CPU 从异常返回,本质上也是跳转到一个地址,并且 ertn 指令后面的指令也不能有任何执行效果。
这里面有一个坑需要注意。
实际上,ertn 指令后面有一系列 0 指令,比如:
1 | |
我会在 IDU 中检测零指令,当拿到 0 指令时,会报指令不存在异常(ine)。
但是 ertn 之后,就算拿到了 0 指令,也不应该报 ine。因此 IDU 在检测到下游传递上来的 ertn 信号后,应该总是置 inst_valid 为 1。
另一方面,当 IDU 检测到下游的异常后,就不应该继续再标记异常了,因为没有意义。当第一个异常被处理后,excp_flush 信号已经被关了:
1 | |
而 excp_flush 依赖的信号想要被打开,就要看 ms_to_ws_valid,这个信号实际上也是被关闭的,因为它是从上游传递下来的。这个信号想要重新打开,只能依赖于 IFU 阶段的 fs_to_ds_valid 重新传递了。此时 IFU 携带的是 异常处理程序的指令。
因此,可以把 etrn_flush 和 excp_flush 重整为一个 flush_sign,因为它们的行为是一致的,即修改 valid,使得各个阶段传递给下游的所有信息在下一周期失效。
但是,这里有一个问题有待解决:某一个阶段的缓存没有更新,它会再执行本阶段,比如 EXU、IDU 重复译码、MEM 重复读取等等,这意味着它会进行重复运算。
好消息是,目前可以认为(实际上重复读取设备中的寄存器并不是这样的,这里暂时不考虑),各个阶段重复计算是一种等幂运算,也就意味着重复运算对于状态机是没有任何影响的,执行一遍、执行多遍是一样的效果。
因此,我们不用考虑缓存的重复执行。但是我们不得不考虑不应该进行的执行。
异常发起后执行 (EAE,Execution After Excption)
EAE 不是什么专有名词,这里为了方便就用 EAE 表示。EAE 表示一种在流水线中常见的情景:
1 | |
可以看到,对于 EXU 阶段在执行 st.w 指令的时候,MEM 单元此时在处理 syscall 指令,这是一个异常;当 WBU 在处理 syscall 指令的时候,MEM 阶段在执行 st.w 指令。
因为 st.w 这个指令不能执行,因为这不符合精确异常的概念。因此,当 EXU 检测到下游有异常的时候,不应该有任何实际的执行效果。对于 IDU、EXU、MEM 同样如此。
具体的说:
- 对于 IDU,检测 EXU、MEM、WBU 是否有异常;
- 对于 EXU,检测 MEM、WBU 是否有异常;
- 对于 MEM,检测 WBU 是否有异常。
换句话说,WBU 如果有异常,MEM 接收到这个信息,通过组合电路传递到 EXU,EXU 接收到这个信息,通过组合电路传递到 IDU。
如果是多个异常呢?
也是一样的,因为只需要处理第一个异常,其他异常都没有任何效果。
ertn 后执行 (EAER, Execution After Ertn)
同样的道理,EAER 也不是什么专有名词,只是为了方便描述。
EAER 描述了这样的情景:
1 | |
和前面的 EAE 类似,当 MEM 阶段持有 ertn 指令的时候,EXU 阶段在处理 st.w 指令。为了实现精确异常,st.w 是不应该有实际效果的。
具体的说:
- 对于 IDU,检测 EXU、MEM、WBU 是否有 ertn;
- 对于 EXU,检测 MEM、WBU 是否有 ertn;
- 对于 MEM,检测 WBU 是否有 ertn。
为什么 ertn 和普通异常这么相似?那是因为不管是异常,还是 ertn 都是跳转到某个地方且不能执行后面的指令缓存,这个和跳转指令几乎一摸一样。
只是有一点和跳转指令不同,那就是真正的跳转地址和信号是在 WBU 阶段发出的,而普通跳转指令是在 IDU 阶段发出的。
设想一下,如果我们的跳转指令的跳转信号也在 WBU 才发出,那么为了实现普通跳转指令,我们也要实现类似于精确异常的机制。
等价的理解是,当 WBU 检测到异常的时候,之前的流水段都不应该产生任何执行效果。什么是执行效果?CPU 是状态机,意味着 WBU 之前的所有指令都不能修改这个状态机的任何状态,这些状态是任何寄存器和存储设备,包括 PC、CSR,以及 data_mem 的写。
这个目的并不很容易达到,当 WBU 发出异常信号时,前面的所有指令缓冲寄存器都应该撤销对 data_mem 的写、对 PC 的写、对 CSR、普通寄存器的写。因此必须要及时关闭写的使能信号。
这里会详细分析每一个模块。
pre_IFU
当 pre_IFU 检测到 flush 的时候,需要设置 next_pc 为 csr 中的 csr_eentry,这个地址保存着异常的处理程序地址。
IDU
idu 检测到 flush 的时候,ds_valid 置 0,意味着这个周期没有处理指令。
EXU
exu 检测到 flush 的时候,es_valid 置 0,意味着这个周期没有处理指令,同时取消访存效果。
MEM
mem 检测到 flush 的时候,ms_valid 置 0。
WBU
这个阶段很关键,因为这个阶段发出 flush 信号。
flush 信号发出的逻辑是:
1 | |
ertn_flush 信号的逻辑是,当前指令时 ertn 指令,并且当前阶段完成处理,同时要求没有其他异常。比如当 ertn 紧跟在 syscall 后面的时候,ws_valid 为 0,ertn_flush 失效。另一方面,ertn 从异常处理程序返回,它身上不可能挂任何异常。
excp_flush 信号的逻辑是,当前检测到异常,且必须是 valid。比如 两个 syscall 连起来,第二个 syscall 并不会产生 excp_flush,因为第一个已经把 valid 置 0 了。
wbu 检测到 flush 的时间,ws_valid 置 0。
总结
可以看到,只要有了 flush 信号,几乎所有的模块都要将 x_valid 置 0,这样,下一个周期,pre_ifu 就会携带着 prefs_valid 和异常处理入口的指令传到 ifu。
精确异常的几个例子
这些例子都来自于测试代码,这些测试代码相当刁钻。
syscall_pc1
1 | |
可以看到,在异常 syscall 之后有一个 bne。按照前面的说法,当 WBU 中检测到了 syscall 异常,才有所作为,事实上早已经晚了。因为 syscall 传递到 EXU 中时,就跳转走了。因此,要及时在 IDU 中检测 EXU、MEM、WBU 所有的异常,而不是仅仅是 WBU 中撤销对 PC 的修改。
syscall_pc2
1 | |
syscall 异常之后,应该撤销对于 st 的执行效果,这很典型。
syscall_pc4
1 | |
这个就要控制 exu 中的除法单元了。因为 exu 中的除法单元是一个多周期,执行时要阻塞exu。如果 WBU 响应异常,而 EXU 阻塞了所有上游,那么 PC 根本无法被修改到 trap_vector,从而引起死循环。
另外,div 之后,还有一个 bne,这个也会尝试修改 PC,因此 EXU 应该将 EXU、MEM 的异常都应该传到 IDU。
syscall_pc7
1 | |
这个在 syscall 后面执行了两条 csr 指令。前者对 0x6 csr 进行了写,后者对 0x6 csr 进行了读。很明显,这发生了 csr 的指数据相关。常见的做法就是采用前递技术,和普通寄存器数据相关的处理方法一致。
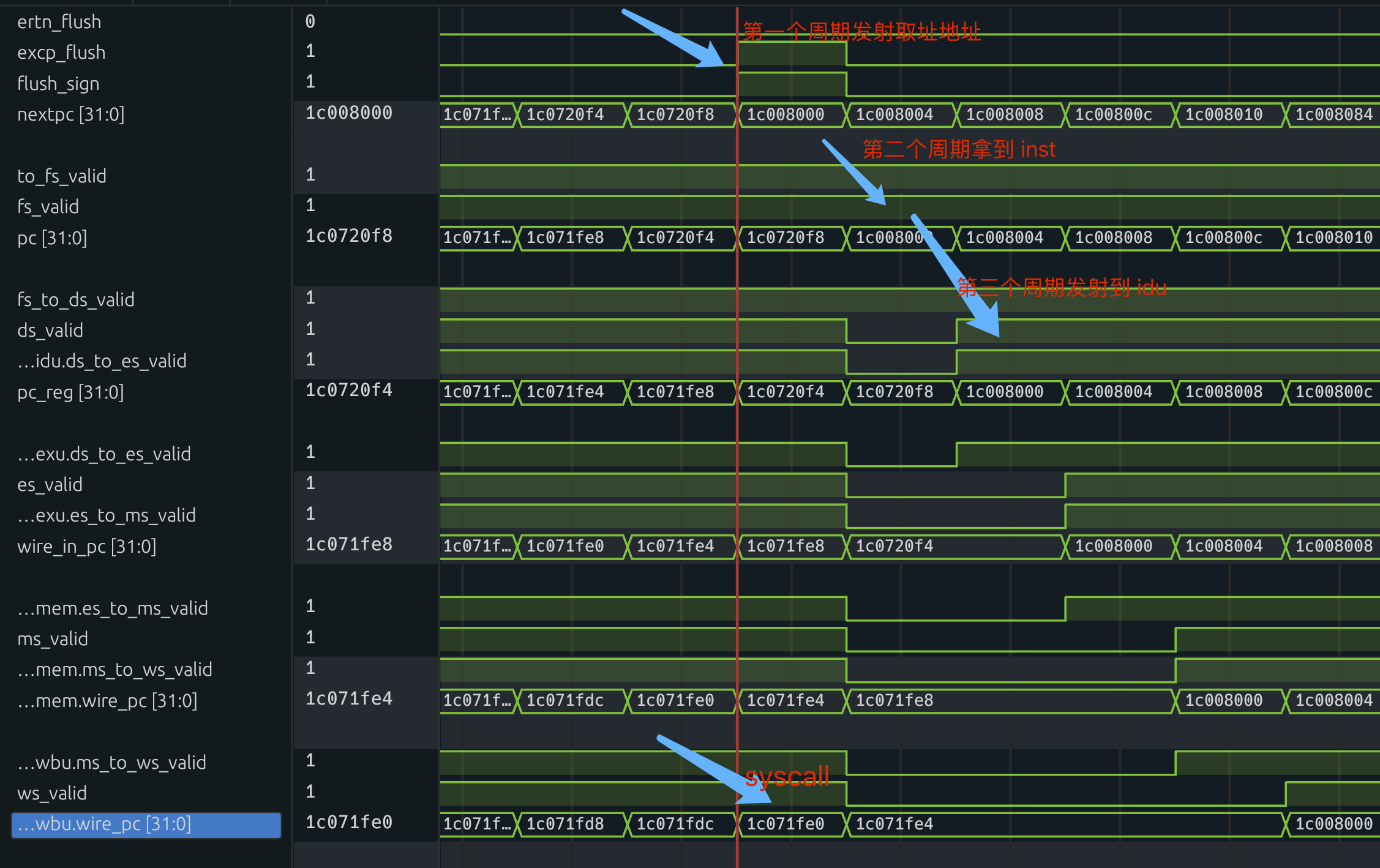
excp_flush
当 WBU 检测到异常的时候,会发生什么呢?
我们希望实现精确异常,也就是说,WBU 前面的所有阶段的指令缓存都不能产生任何执行效果,不能修改任何状态机(寄存器、内存)。
因此,WBU 要将这异常信号,发送到 CPU 的各个处理单元,下一个周期时,所有的单元都会处于非处理状态,直到 IFU 将指令发射到 IDU 中。流水中就会重新填满新的指令~
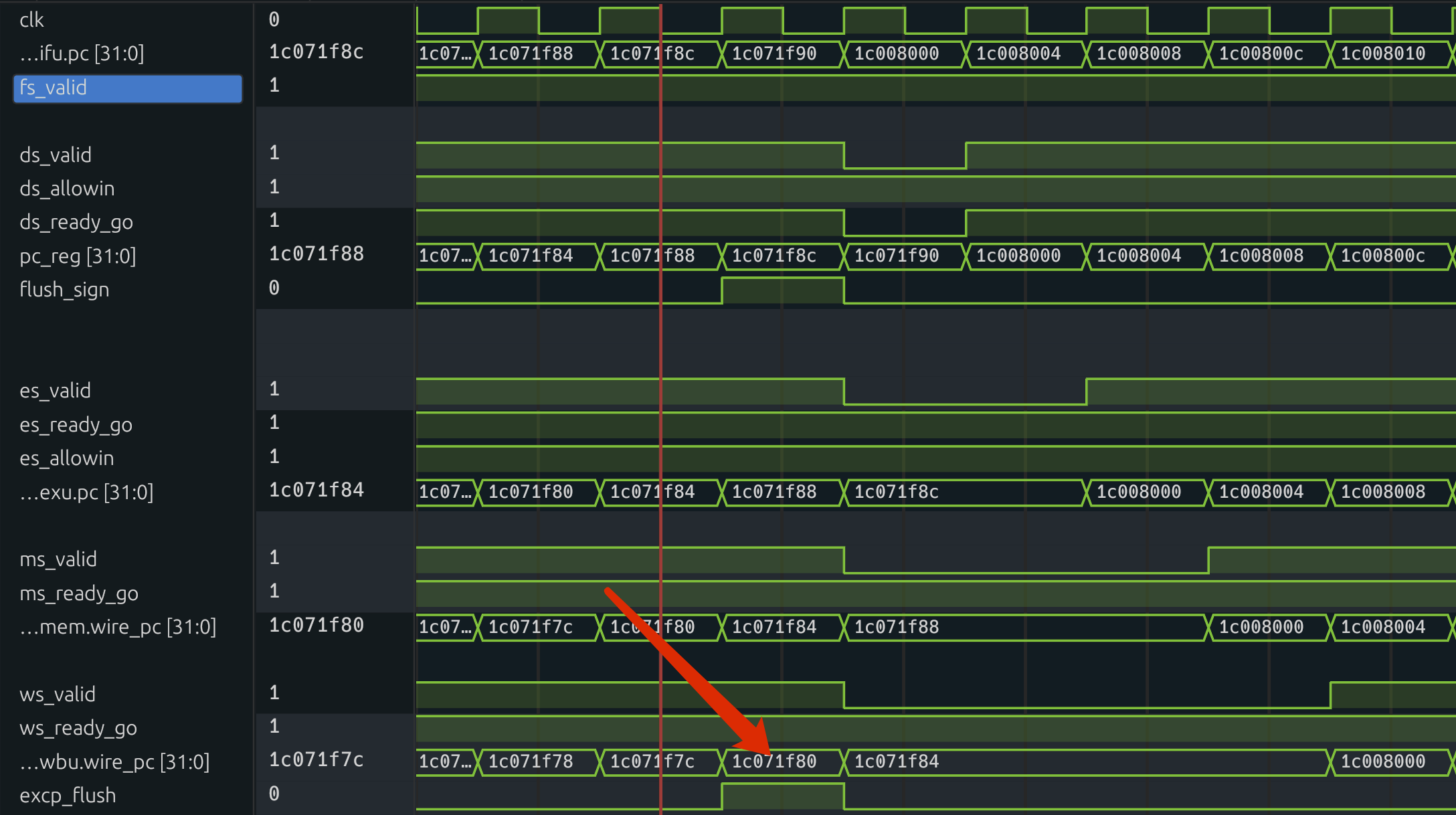
ertn_flush
这个和 excp_flush 完全一致。都是刷掉没用的指令缓存。
tid 数据相关
有一种情景:
1 | |
第一条指令往 csr_tid 中 写值,第 3 条指令读出这个值,但是很明显此时读出的值是错的,因为第一条指令还没有完成写。这时候,可以利用数据前递技术(算是复用了前面的方案)。
1 | |
这样,就完美解决。