浅谈二进制安全(一)
基于 x64 的 Linux 函数调用过程
caller 在 call 以及 call 之前、callee 在 ret 以及 ret之前都会做一些事情,以有序得执行程序。
比如,对于 main 函数调用 add_ints:
1 | |
在编译参数为 gcc -O0 -fno-omit-frame-pointer -g -no-pie -masm=intel abi_demo.c -o abi_demo 的时候,部分反汇编代码如下:
1 | |
首先 main 函数将参数放到 edx、esi、edi 中,然后 执行 call。
这个 call 指令有几个含义:
- 首先会将 call 指令后面一条指令的地址,也就是 ret_addr 存储到 rsp -= 8 中,也就是 push 了一次 ret_addr;
- 接着跳转到 add_ints。
到达 add_ints 后(暂时忽略 endbr64),接着将 caller 也就是 main 的 ebp push。然后开辟新的栈帧,此时 rsp 指向了保存 caller 的 ebp,新的 ebp 保存的是 rsp。从这里就可以看到,新的栈帧是从保存 caller 的 ebp 开始的。
接着就开始执行函数功能代码了。
执行完了后,由于 rsp 指向的是 caller 的 rbp,因此这里直接 pop rbp 来恢复 rbp(下面会介绍稍微复杂的情况),此时 rsp -= 8,指向的是 ret_addr。之后就是 ret,这个 ret 的时候 ,会把 rsp 保存的 ret_addr 直接赋给 rip,也就是相当于 pop rip。
在 x86-64 上,近返回指令 ret 的语义本质上就是“从栈顶取返回地址到 RIP,同时弹栈”,可以理解为“pop + 跳转”。这样调用函数完后,main 就会返回继续执行。
因此在 callee 的栈从高地址到低地址(示意)是:
1 | |
以上就是函数调用和返回的细节。
ROP 攻击
ROP 攻击是利用程序将 saved_rip 保存在栈上,用户可以修改从而改变返回地址的攻击方法,这样可以劫持 caller 的返回点。
示例代码
1 | |
编译
为了让这个示例成功,我们需要关闭所有现代安全保护。在 x64 Linux 上,需要使用以下命令来编译代码:
1 | |
寻找目标地址和偏移
为了成功利用栈溢出,我们需要知道三个关键信息:
- evil_function 的地址:这是我们想要劫持程序跳转到的目标地址;
- vulnerable_function 中 buffer 变量到 saved_rip 的偏移量:我们需要填充多少字节来到达并覆盖返回地址。
1. 找到 evil_function 的地址
1 | |
2. 找到 buffer 到 saved_rip 的偏移量
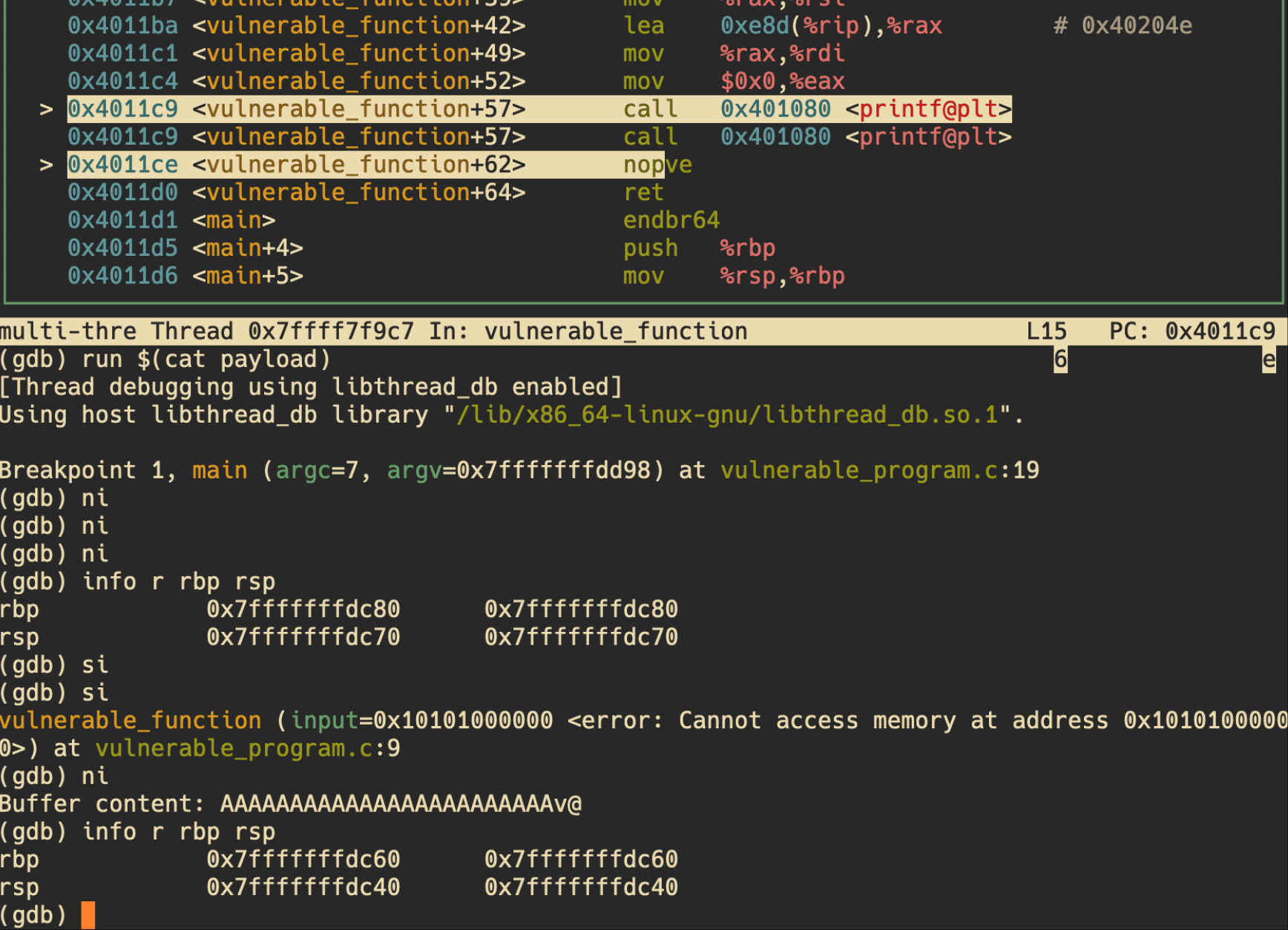
我们可以在 vulnerable_function 中设置一个断点,然后观察 buffer 和栈上返回地址的内存位置。
1 | |
这样看得更更清楚:
1 | |
1 | |
可以看到此时 saved_rip 是 0x40122,这正是 call 401190 <vulnerable_function> 语句的下一条指令地址,main 会在 vulnerable_function 函数执行完后返回到这里。
通过计算,我们得到偏移量:0x7fffffffdc98 - 0x7fffffffdc80 = 0x18 = 24字节。
这表示我们需要用24个字节来填充缓冲区,然后才能开始覆盖 saved_rip。
3.构造攻击载荷
现在有了所有必要的信息:
填充字节数:24
目标地址:0x401176
攻击载荷将由两部分组成:
- 24个填充字节,用于溢出 buffer 和栈帧的其它部分。
- 8个字节,用于覆盖 saved_rip,这8个字节是 evil_function 的地址 0x401176 的小端字节序表示。
在shell中,我们可以使用Python来方便地构造这个载荷。
1 | |
b”A”*24:24个ASCII A 作为填充字节。
b”\x76\x11\x40\x00\x00\x00\x00\x00”:0x401176 的小端字节序表示。
执行攻击
1 | |
如果一切成功,程序会首先打印出被溢出的缓冲区内容,然后,当 vulnerable_function 试图返回时,它会从栈上读取到我们注入的 0x401147 地址,并跳转到 evil_function。
改进
可以看到,尽管攻击成功地劫持了程序流并执行了 evil_function,但随后的段错误表明程序在 evil_function 返回时再次崩溃了。
它会尝试从栈上弹出一个返回地址。然而,栈上并没有为 evil_function 放置一个有效的返回地址。evil_function 从栈上弹出一个无效或随机的地址(通常是攻击载荷中的剩余数据),并尝试跳转到该地址。这个无效的跳转导致程序访问了一个未分配或受保护的内存区域,从而触发了段错误。
解决方案:构造完整的 ROP 链
需要构造一个更完整的 ROP 链,以确保 evil_function 返回后,程序能继续执行有效指令。
最简单的解决方法是,让 evil_function 返回到 main 函数中 vulnerable_function 调用之后的地址。
攻击载荷的新结构
- 24字节填充:覆盖 vulnerable_function 的 buffer;
- 8字节 evil_function 地址:劫持程序流到 evil_function。
此时函数从 vulnerable_function 返回后,本来应该返回到 main 中,但是此时却返回到了 evil_function,我们需要明白这中间的所有细节。
假设此时在 vulnerable_function 中,栈如下表示
1 | |
使用攻击载荷之后,在执行 vulnerable_function 的返回代码之前:
1 | |
关键内存(saved_rip)数据如下:
1 | |
前面知道,leave、ret 两个指令的 作用是:
- mov rsp, rbp ; pop rbp
- 从 [rsp] 弹出 8 字节到 RIP 并跳转
那么 vulnerable_function 执行完 leave 之后,rbp 被篡改,rsp 恢复到 main,saved_rip 篡改到 evil_function。
换句话说,到目前为止这执行流看起来正确,其实栈的控制、寄存器的控制都是错误的。接下来仔细分析程序执行的细节:
程序过程
main 的 rsp、rbp(带有攻击载荷):
rsp 恢复到了 main,但是 rbp 已经被篡改:
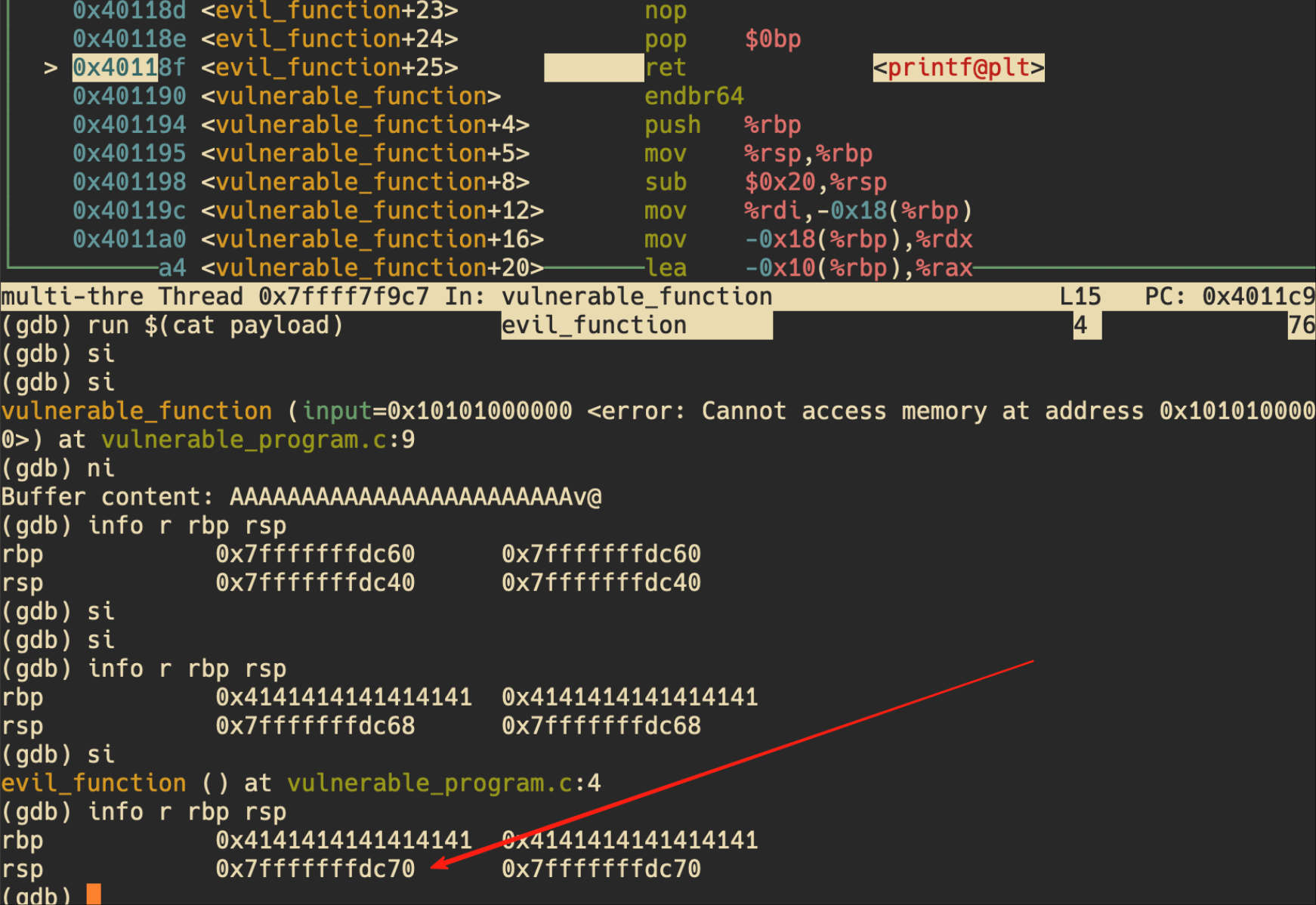
因为 rbp 是错误的,因此 evil_function 执行 ret 的时候,肯定有问题。因此必须在构造载荷的时候,得让 rbp 恢复到 main,这样 evil_function ret 的时候,和 main 执行 ret 等价。
新的载荷
24字节填充:覆盖 vulnerable_function 的 buffer。
8字节 evil_function 地址:劫持程序流到 evil_function。
8字节 main 函数中的返回地址:确保 evil_function 返回时,程序能回到 main 函数中正常结束。
我希望,能构建这样的载荷:
1 | |
它能够将正确的值,也就是原来的 main 的 rbp 正确恢复。但是事实上不成功:
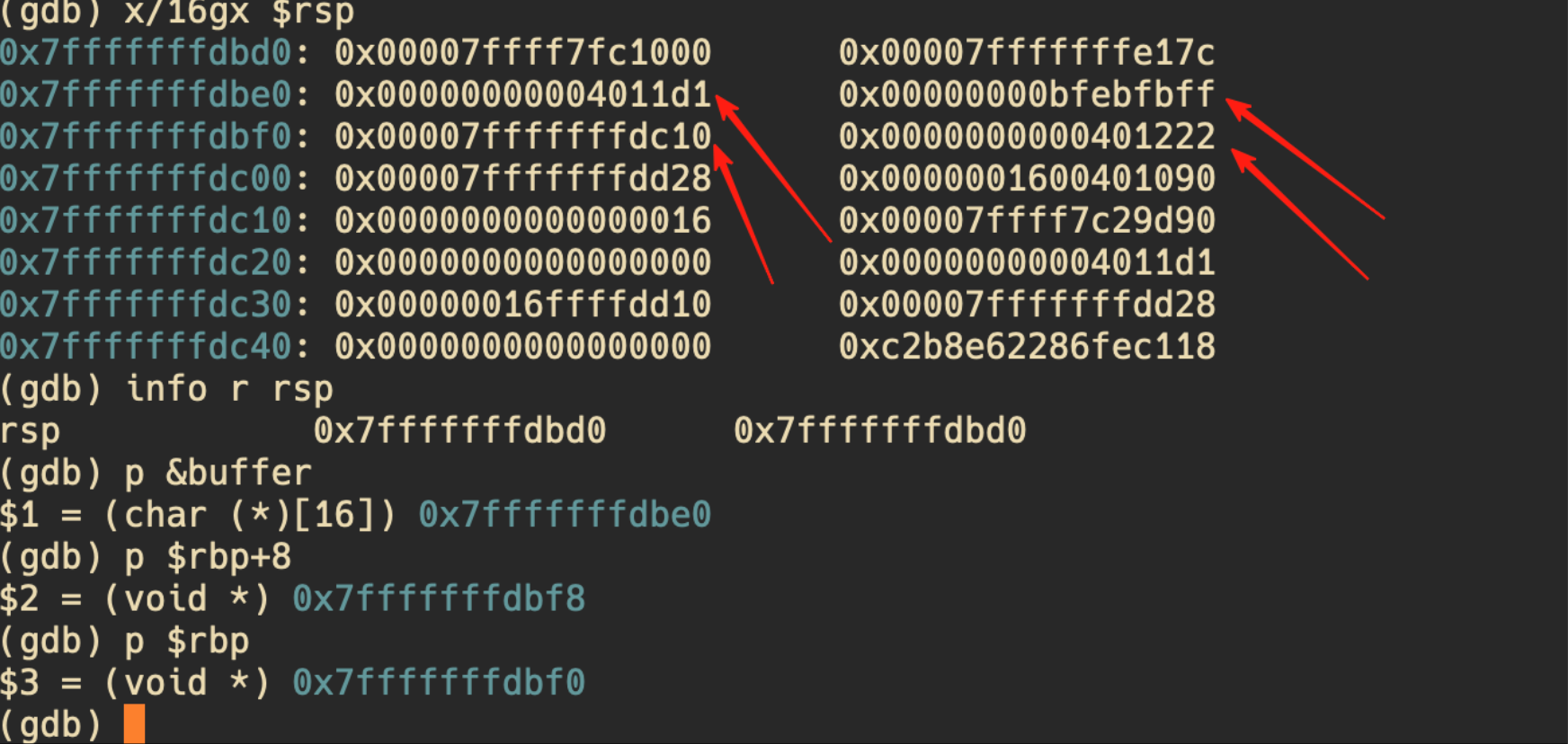
一共 32 B 的载荷,只有前 8 个字节被覆盖到,后面就没动。为什么?原来这个和 strcpy() 特性有关:strcpy/printf(“%s”) 这类按 C 字符串的函数,会一直拷贝直到遇到第一个 \x00。
也就是说,实际上载荷只拷贝了 3 个字节。
这样,我们的载荷构建就有很大的局域性,它严重依赖于载荷中没有/00 这样的字符。事实上这几乎是不可能的,因此现在阶段,只能劫持到 evil_function,想让它顺利执行完并返回到 _start 条件太严格。
ROP 防护
针对 ROP 攻击,有多种防护方法,几乎是组合拳同时起作用,这样 ROP 攻击很难成功。
金丝雀
栈金丝雀是一种“改就报警”的哨兵值。流程是:
- 程序/线程启动:运行库生成一个不可预测的 64 位随机数并放到 TLS(fs:0x28)。
- 函数序言(prologue)里插桩(编译器自动加的指令):
- 从 TLS 取金丝雀,拷贝到当前栈帧(例如 [rbp-0x8])。
- 只有当函数“看起来有溢出风险”(见后面的触发条件)才会插。
- 函数尾声(epilogue)里插桩:
- 再从 TLS 取一遍金丝雀,与栈帧里的副本比。
- 若不相等 ⇒ 说明栈从局部变量往上被破坏过 ⇒ 立即调用 __stack_chk_fail 终止(通常 abort()/产生错误日志),不再执行 ret。
常见的序言/尾声指令大致是:
1 | |
对比
没有金丝雀-fno-stack-protector:
1 | |
加上金丝雀-fstack-protector:
1 | |
可以看到多了一些额外的代码。这类由编译器自动插入的额外检查代码就叫“函数插桩(instrumentation)”。开编译选项,符合条件的函数编译器会自动加上。
从 TLS 读金丝雀到 RAX,再写入本帧的金丝雀槽位 [rbp-0x8]。
- TLS(Thread-Local Storage):每个线程私有的小数据区;x86-64/Linux 下以 fs_base 为基址。
- fs:0x28:glibc 约定 TLS 中 __stack_chk_guard 的偏移(每线程一个 64 位随机值)。
经典“覆盖返回地址”的路径是:局部缓冲区 → 往高地址写 → 先碰到金丝雀 → 再是 saved RBP → 再是 saved RIP。
有了金丝雀:
- 一旦跨过金丝雀,尾声校验就会失败,函数在 ret 之前就被中止,无法跳到“伪造的返回地址”;
- 金丝雀不可预测(每线程随机),攻击者若想绕过必须提前泄露金丝雀的值并“准确重写”,这显著提高了攻击成本;
- 编译器还会对局部变量重排(如把指针/标志放在数组上方),进一步降低“越界不经意间覆盖关键控制数据”的概率(具体取决于实现)。
现在有了金丝雀,我们再次尝试刚才的攻击。
再次攻击
构建好载荷之后,再次攻击,发现金丝雀被改变了:
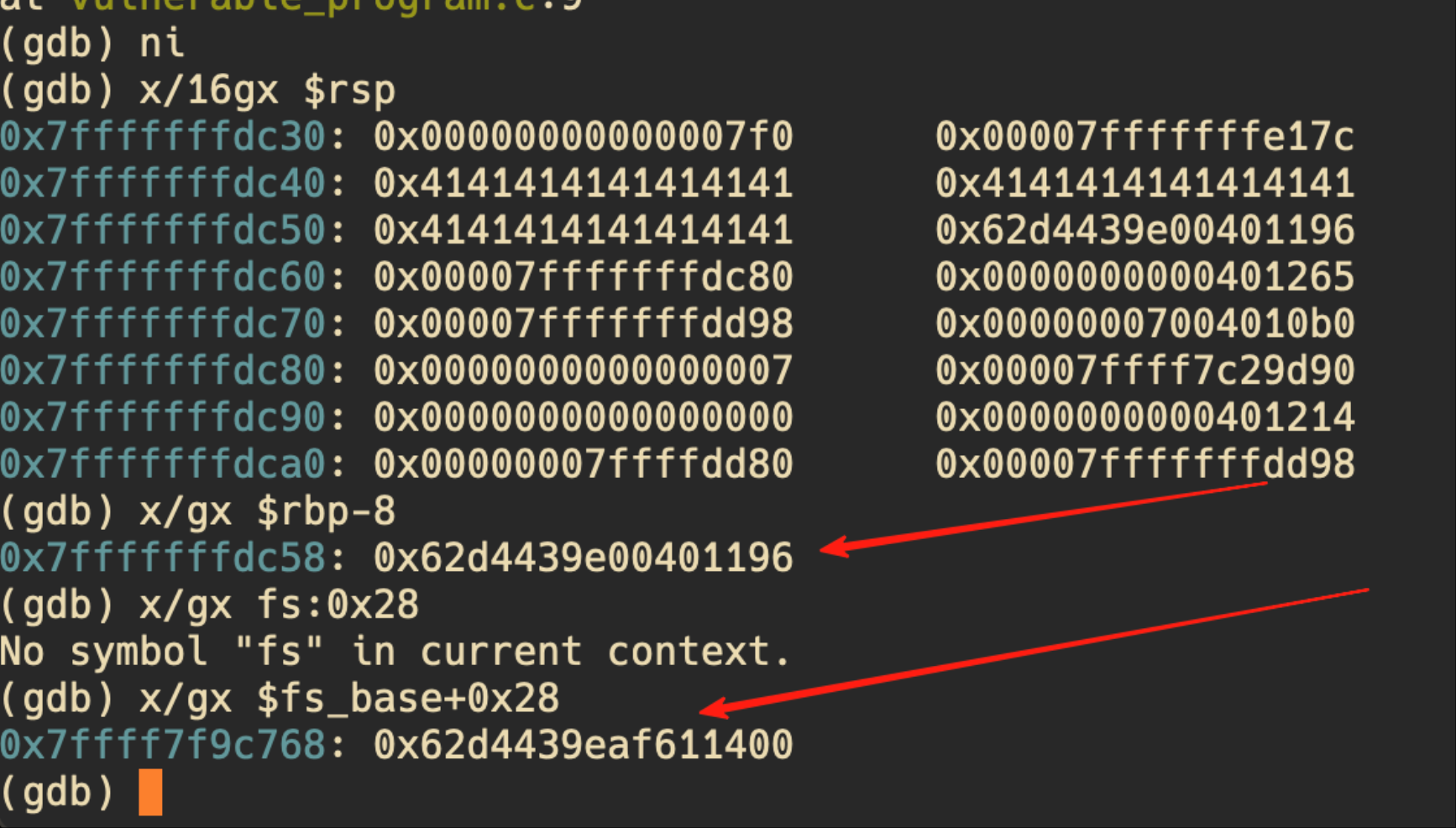
我们继续运行,看看报什么错误:
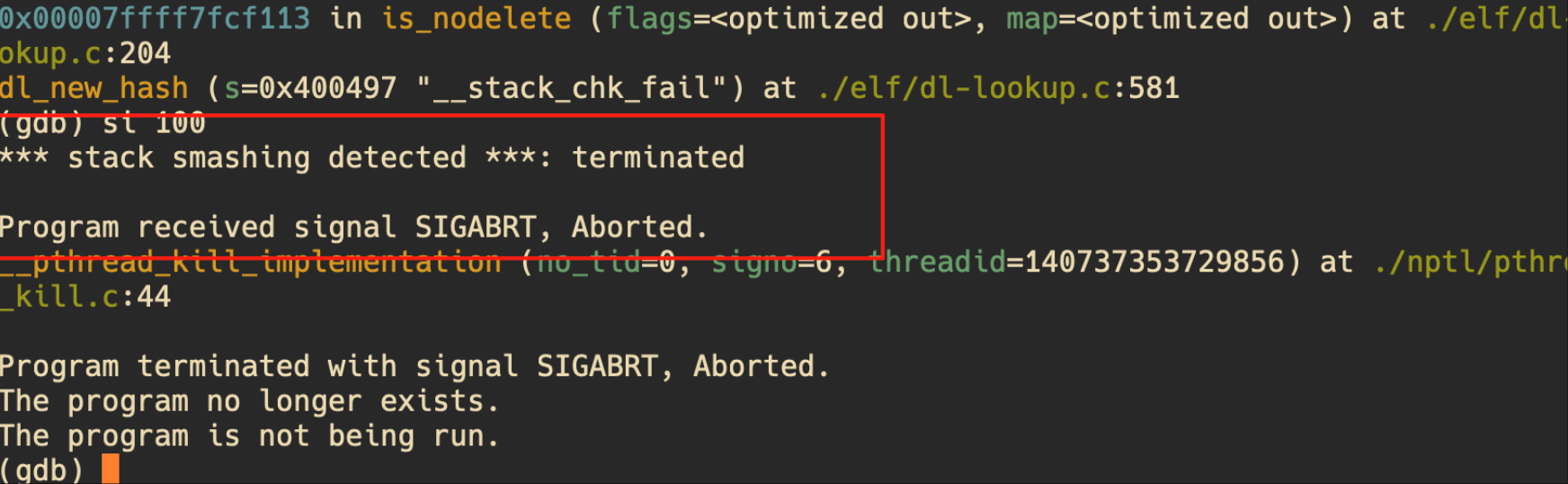
金丝雀成功阻止了此次 ROP 攻击,运行也是不成功的:
1 | |
影子堆栈
SHSTK(Shadow Stack,影子栈)——硬件保存返回地址的“只读真相”,CPU 维护一份与普通栈分离的影子栈(有自己指针 SSP)。
- 每次 call:返回地址同时写到普通栈和影子栈;
- 每次 ret:把普通栈上的返回地址与影子栈顶部比较;不一致 → #CP。
由于进程无法随意写影子栈(页只读,需特殊指令),ROP/栈 pivot/ret-sled 会被当场抓住。
由于这项技术在 Intel 11 代之后才支持,无法做这个实验。
CET
Intel 的 CET主要有两大类:影子堆栈和 IBT:
| 能力 | 拦住 | 说明 |
|---|---|---|
| Shadow Stack | 经典 ROP、ret-sled、栈 pivot(经 ret) |
ret 与影子栈不匹配立刻 #CP |
| IBT | JOP/COP(间接 jmp/call 不落在 endbr64) |
落点非法即 #CP |
| 两者叠加 | 绝大多数代码复用攻击(ROP/JOP/COP 组合) | 需要配合其它硬化形成完整链路 |
| 仍需其它硬化 | 覆盖函数指针/虚表、覆盖 GOT、信息泄露、逻辑漏洞 | 用 CFI(Clang)/RELRO+NOW/PIE+ASLR/NX/W^X/Canary/沙箱 等叠加 |
而金丝雀(Stack Canary)是软件/工具链层面的防护,主要由编译器 + C 运行库 + 内核提供的随机性协同完成,不是硬件特性;它并不只存在于 Linux——BSD、macOS 也有;Windows 上对应的是 /GS“security cookie”。在 Linux/x86-64 下常看到的 mov rax, qword ptr fs:0x28 就是它的典型实现细节之一。
和 CET 的关系:
- 金丝雀:软件插桩,主要拦线性栈溢出覆盖返回地址;
- 影子栈(CET-SHSTK):硬件保存返回地址副本,ret 时强校验,一旦被改立即异常,专治 ROP;
- IBT(CET):要求间接跳转落在 endbr64,专治 JOP/COP。