分支预测技术
基于 2 bit 饱和计数器
原理就是利用 PC 中 k 位来查找 PHT,若查到了一个表项,那么就可以由 PHT 中的一个表项的 2bit 饱和计数器给出跳转建议。这个 2bit 饱和计数器其实就是一个跳转意愿强度:00、01、11、10(格雷码)。而从指令提交阶段的跳转指令的反馈信息(比如是否发生了跳转)可以更新这个饱和计数器。
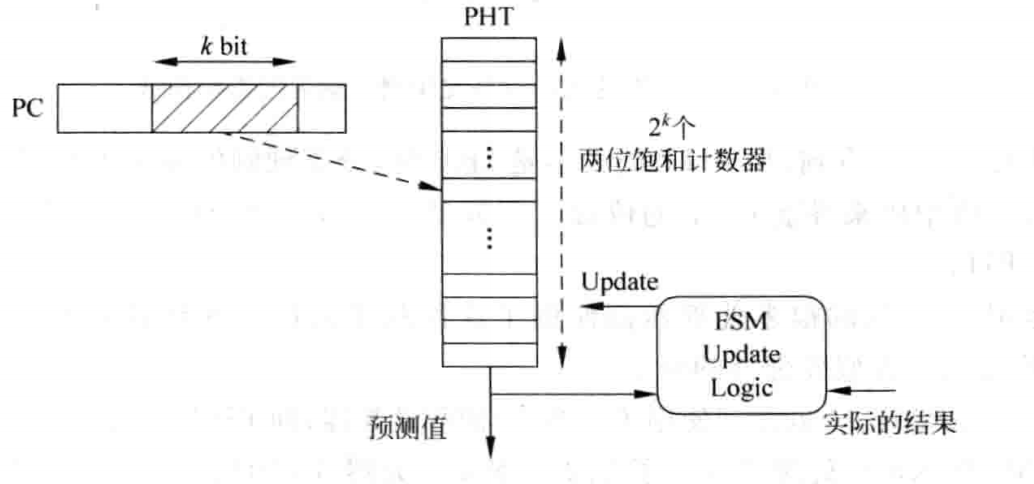
PHT(Pattern History Table)
PHT 存放着所有 PC 值对应的 2bit 饱和计数器的值,是一张表。现实中这显然不可能,因此只能存放 PC 的一部分值,比如 k 位。这导致了不同的 PC 映射到了同一个表项,这会造成干扰。因此,可以考虑用一个哈希,来尽可能避免冲突。
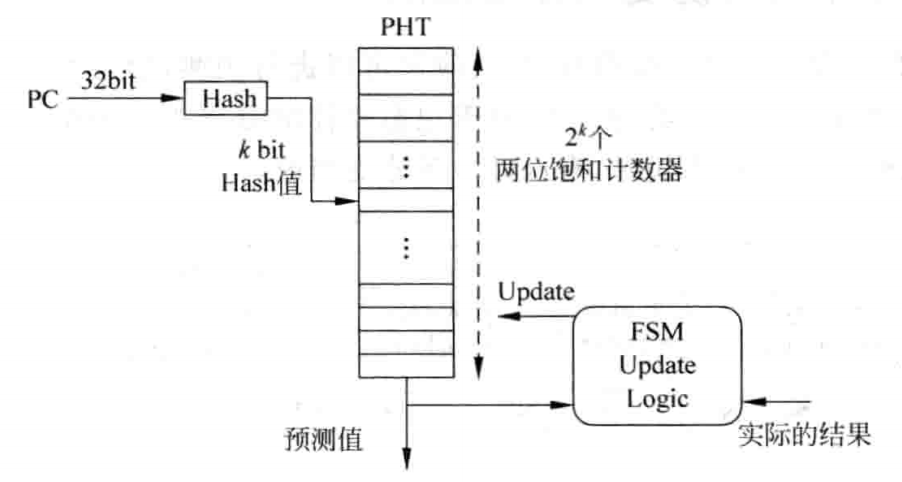
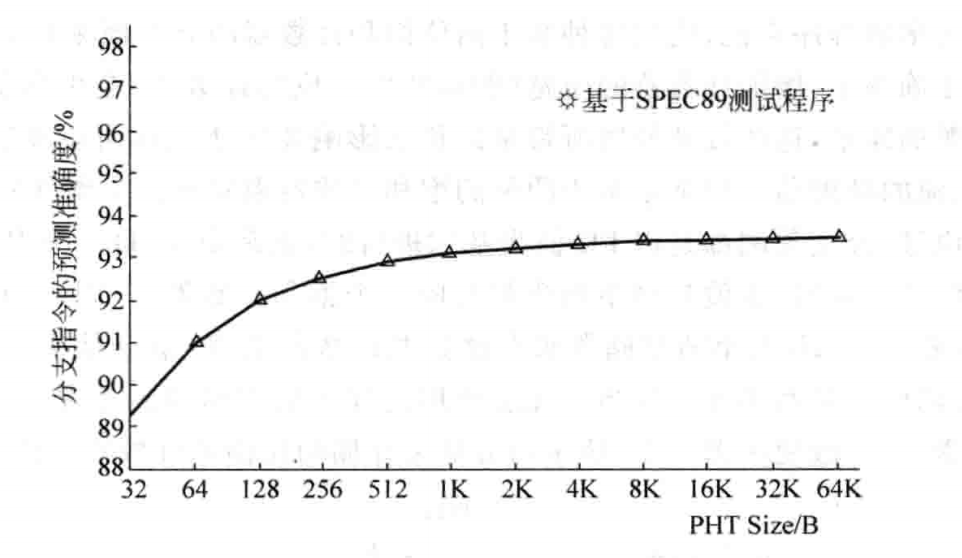
表越大,这种冲突可能性就越小。但表如果太大,就会造成资源的过度消耗,因此要有一个折中。当表太大的时候,对准确度的提升就很小了,因此可以选一个合适的。比如选 10 bit,此时 就对应着 2^10,也就是 1K 项,即 2bit * 1K = 2Kb 大小。
BTB
这是跳转指令的 PC 对应的跳转目标组成的表。
评价:这种基于 2bit 饱和计数器的分支预测方法的正确率很难到达 98% 以上的正确率。因为它对历史跳转情况过度抽象,抽象成了一个强度值,比如 0、1、2、3,这完全屏蔽了真实的历史情况。这就是它性能(准确率)低的真实原因。
因此,想要提高性能上限,就必须得对历史重新审视,甚至保留一部分历史,不要做任何抽象。这有点像机器学习,如果学习不足,就会导致抽象度过高;如果学习过度,就会导致抽象出来的模式太多,浪费资源。
基于局部历史的分支预测(和基于 2 bit 饱和计数器)
对于某一个跳转指令,它保留了部分历史,并把这部分历史保存在 BHR 寄存器中。然后根据 BHR 的值,对应到一个 PHT 的项,而这个项就是 2bit 饱和计数器,反应出了这段历史模式的跳转建议。
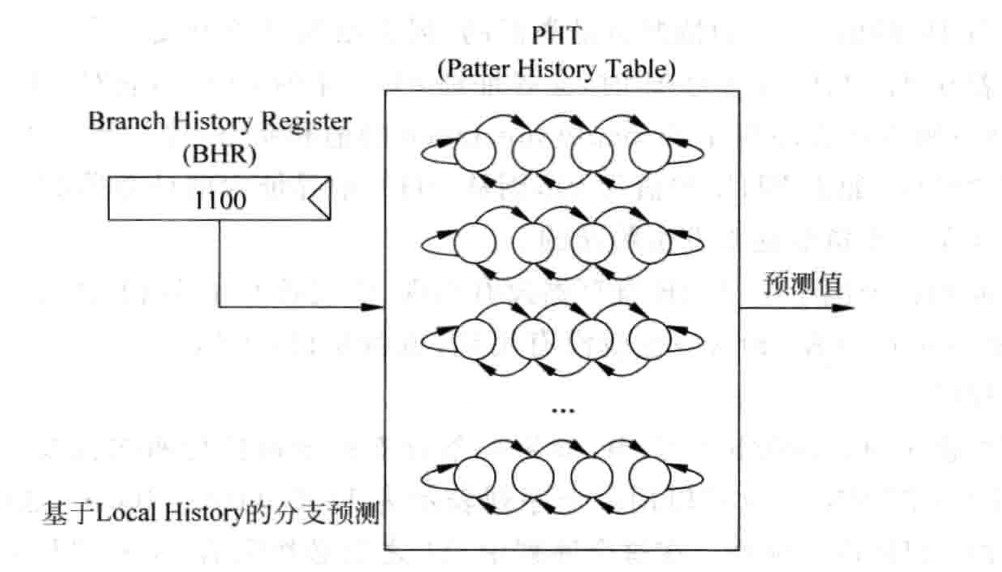
对于 PHT,依然会对 2bit 计数器进行更新。
这个原理完成了对某一个跳转指令的历史保存、历史模式识别、给出跳转建议。
考虑长度为 4 bit 的 BHR,它产生的模式一共有 16 个,因此需要有一个 表长度为 16 的 PHT,就像这样:
![]()
有时候,某些跳转指令的 4bit 历史模式并没有这么多,这就造成了浪费。
不难发现,对于一个有着历史规律的跳转指令,它的周期如果是 3,那么只要使用长度不小于 3bit 的 BHR 就可以对其进行预测。
循环周期的计算方法,比如 11100_11100_11100,这样的模式周期就是 3,3bit 长度就能完全确定当中的任何一个模式。
BHT(Branch History Register Table)
以上的讨论有一个前提,那就是每一个分支指令都有一个 BHR 以及对应着一个长度为 2^k 的 PHT。
将所有的跳转指令的 BHR 集合在一起就形成了 BHT。但是就像上面 的例子,不可能对每一个 PC 都创建一个 BHR 以及对应的 PTB,可以在 PC 中选取长度为 k 的索引,让这个索引去找对应的 BHR、PTB:
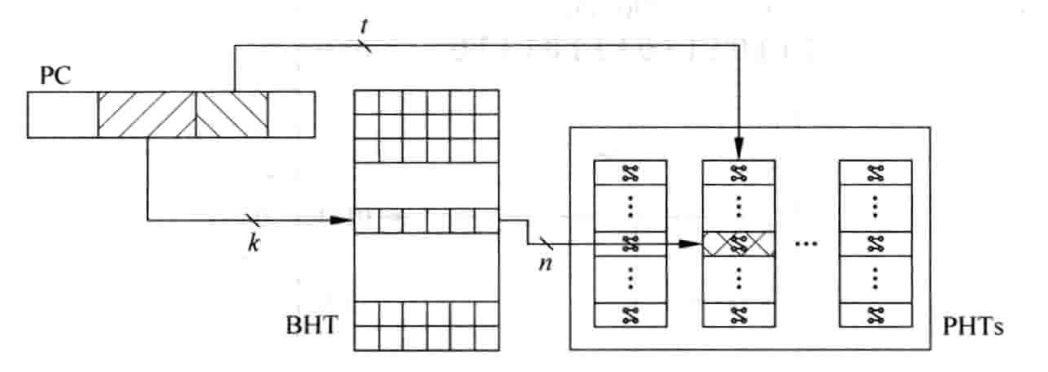
遇到冲突产生重名也是正常的,虽然会对性能产生影响。
上述的图中,虽然只用了 PC 的中部分 k 位,但消耗的资源还是不可接受的。
PHTs 的退化
前面提到,由于 PHTs 中的某一个表中的模式可能耗费不完,会有浪费。因为一个 BHR 对应的 PHT 根本用不完,因此可以将所有的 PHTs 退化为一个 PHT,所有的 PC 共用。当然,这样肯定会造成干扰,但这是一个折中:
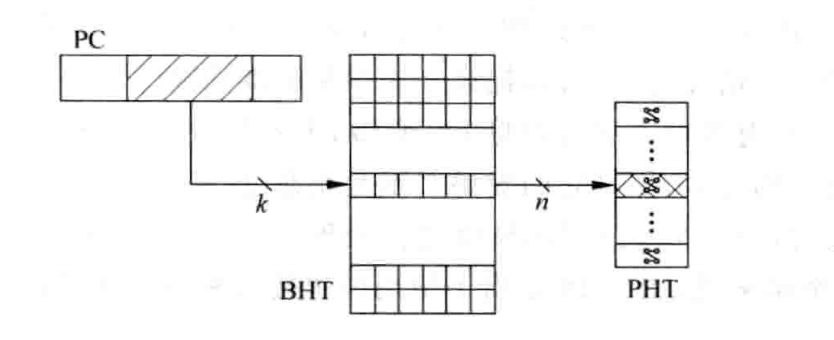
为了能最大限度不浪费资源并且降低干扰或者冲突,可以使用哈希算法,将 PC 的值和对应的 BHR 值进行一定的处理:
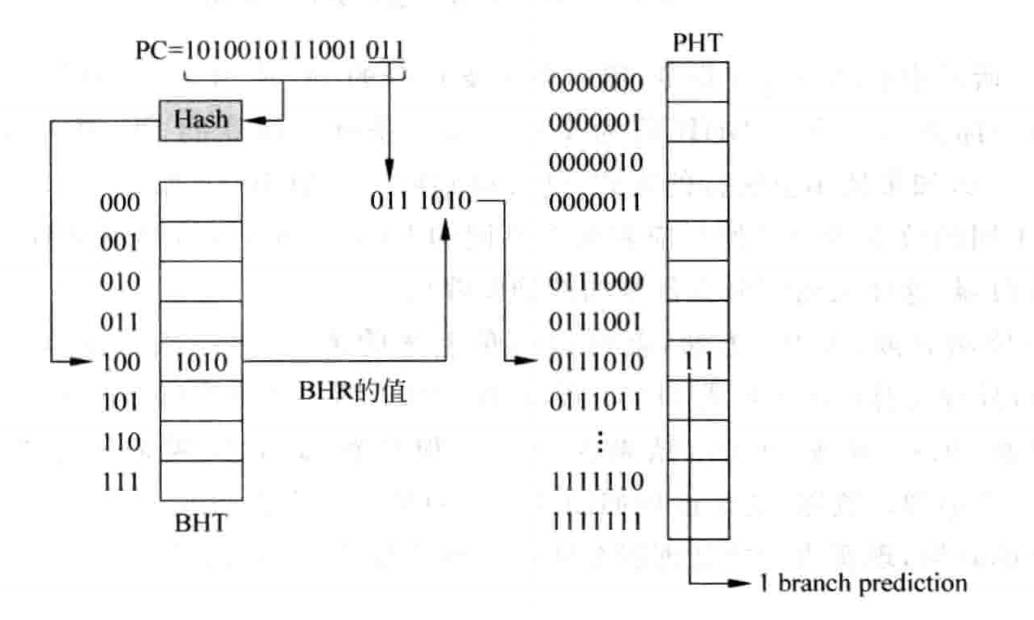
评价:对某一个指令的历史进行了模式识别,对不同的模式分别进行饱和计数。但这是只对自己的模式进行了识别。实际上,某一个指令是否跳转,还要看其它分支指令的影响,毕竟代码中出现条件嵌套、条件依赖的情况很常见。
基于全局历史的分支预测(和基于 2 bit 饱和计数器)
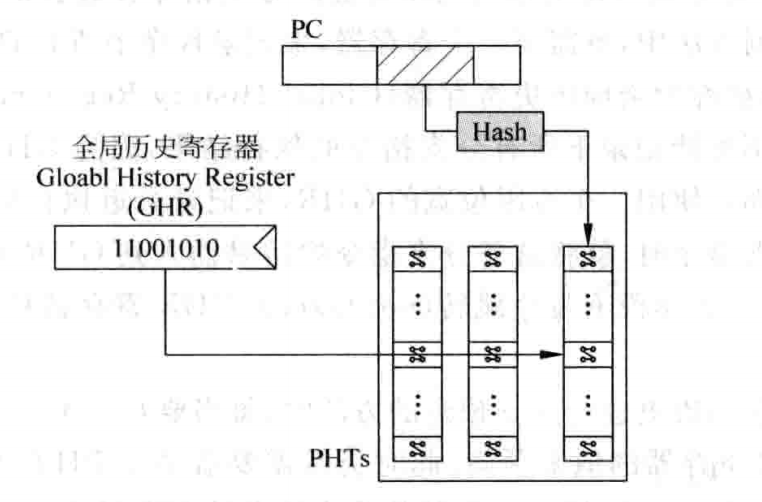
基于局部历史的分支预测方法中,一个 BHR 值记录某一个跳转指令的历史情况。而在基于全局历史的分支预测中,它会记录任何跳转指令组成的跳转记录,存在 GHR(Global History Register)中。
现实中,不可能记录所有的分支指令历史,因此只记录一段历史,通过移位进行更新 GHR。当某一个分支指令被预测的时候,查找 PHTs 来找到对应的的跳转指令( 当前跳转指令的PC)的 PHT,然后根据 GHR 锁定一个 PHT 选项,找到饱和计数器的值。
而基于局部历史的分支预测中,一个分支指令的 PC 只会锁定 BHR,根据 BHR 来锁定退化的 PHT 中的某一个项,找到饱和计数器。
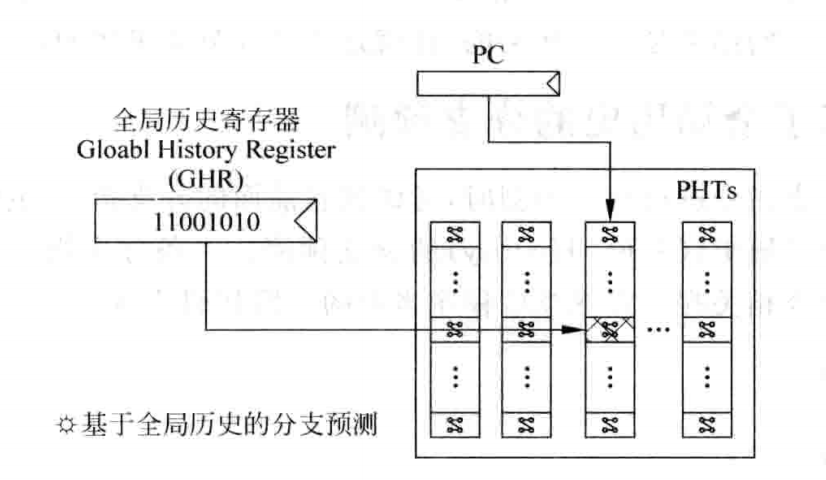
基于全局历史的分支预测器的思路是保持一个 GHR,GHR 是被运行程序的最近跳转的历史。而基于局部历史的分支预测不同,它有很多的历史,几乎(PC 的一小段)为每一个跳转指令都准备了 BHR。
考虑到一下程序:
1 | |
这个在执行的过程中,GHR 就会和 BHR 一致。考虑下面的程序:
1 | |
对于 GHR,循环内循环的时候,GHR 会被更新,GHR 里面都是内层循环的历史,外层循环的历史将会被冲掉。但是对于 BHR,这不会发生,BHT 将会把这两个循环的跳转历史都会保存下来。这样,似乎 BHR 更占优势?
PHTs
和基于局部历史的分支预测一样,为每一个 PC 单独设计一个 PHT 不现实,因此可以采用哈希算法将 PC 进行处理,这样会大大减少 PHT 的使用量了:
《超标量处理器设计》这本书中到,当基于局部历史的分支预测器的 BHRs 退化到只剩一个 BHR 的时候,就变成了基于全局历史的分支预测方法了。我认为不妥,因为基于局部历史和基于全局历史的思路完全不同,这两者虽然形式可以相似甚至一致,但是内涵完全不同,没有任何彼此抽象的理由。
如果更激进点,将已经优化得更少的 PHTs 直接退化为一个 PHT,那么就会变成这种情况:
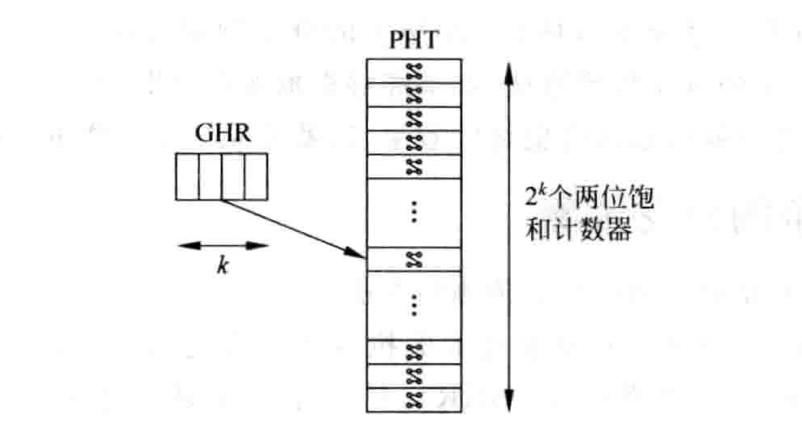
这将会和原来的基于全局历史的分支预测方法完全不同。原来的 PHTs 会根据不同的 PC 找到不同的 PHT ,然后根据 GHR 查找已经锁定的 PHT 选项,从而找到饱和计数器。这种设计甚至是无法工作的,因为所有的 PC 都会使用同一个 GHR,找到相同的饱和计数器。
解决思路是,必须让 PC 和 PHT 进行关联:
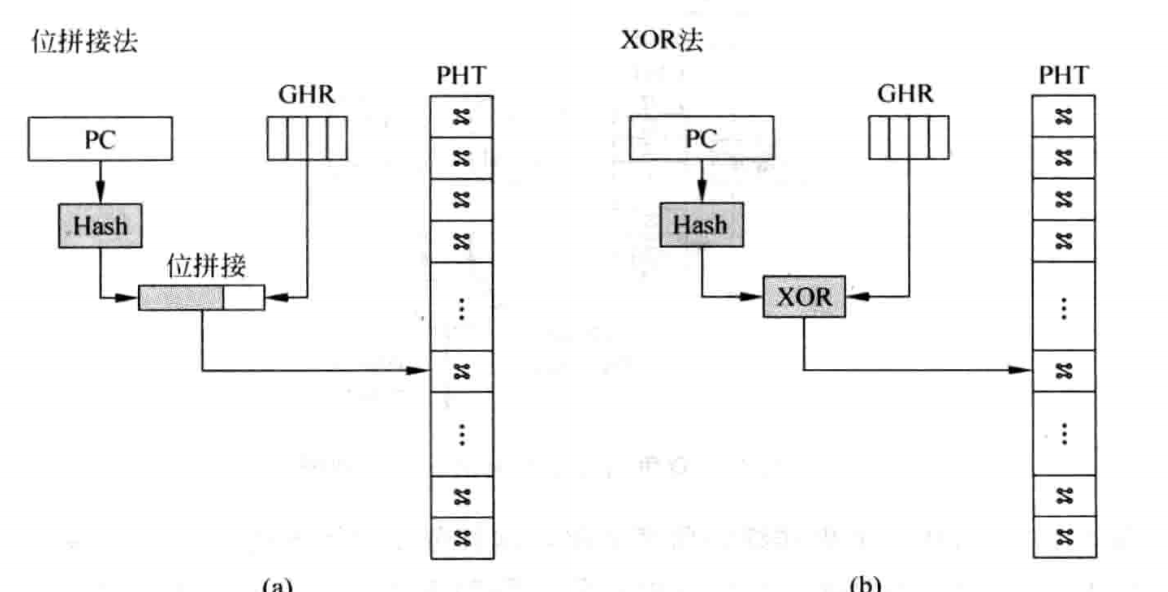
这样,有了全局历史的同时,也能让不同的跳转指令选择不同的 PHT
选项,从而有不同的饱和计数器。
总结一下就是:
分支预测技术的演进:从抽象到精细,从局部到全局
1. 基于饱和计数器的分支预测:简单抽象的智慧与局限
每个分支指令通过PC值索引到PHT中的特定计数器,该计数器承载着指令的历史行为抽象。这种方法的核心思想是将复杂的历史执行轨迹压缩为单一的统计量——一个反映”跳转倾向”的数值。
优势:实现简单,硬件开销小,能够捕获基本的行为趋势。
根本缺陷:信息过度压缩。将丰富的历史模式简化为单一数值,必然丢失重要的上下文信息和时序特征,导致预测精度受限。
2. 基于局部历史的分支预测:精细化建模的得与失
针对每个分支指令维护专属的历史模式表,不同的历史序列对应不同的饱和计数器。这种方法摒弃了粗粒度的统计抽象,转而采用细粒度的模式识别。
优势:能够识别和利用指令特有的执行模式,预测精度显著提升。
根本局限:过度局部化。每个指令孤立地依据自身历史进行预测,忽略了程序执行的全局上下文和指令间的相关性,在复杂控制流中表现不佳。
3. 基于全局历史的分支预测:局部与全局的智慧融合
通过全局历史寄存器(GHR)记录程序的整体执行轨迹,然后结合分支指令的PC值共同索引PHT。这种设计体现了系统性思维:既保持每个分支的个性化预测表,又将其置于全局执行上下文中。
核心洞察:分支行为不是孤立的,而是程序全局状态的函数。当前分支的跳转决策既依赖于自身特性,更取决于程序当前的执行路径和状态。
设计哲学:在局部精确性与全局一致性之间找到最佳平衡点,实现了”既见树木,又见森林“的预测策略。
最终的启示是:最优的系统设计往往不在于单一维度的极致,而在于多个维度的智慧平衡。