预测器关键参数
分支预测器的性能指标
上一篇文章研究了一个供学习研究的分支预测器 biriscv_npc,顺便量化了这个分支预测器的性能(唯一指标就是分支准确率,已经包含各个分支指令执行次数的权重,想想为什么)。
这篇文章来研究各个参数对于分支预测器的影响,以及为什么影响。
BTB 容量
处理器的 BTB 大小是有限的(比如 512 个条目)。当需要存入第 513 个分支指令的预测信息时,必须覆盖掉某一个旧条目。选择覆盖哪个条目的策略就是替换策略。
如果 BTB 采用顺序替换(例如,LRU 或 FIFO,但顺序访问是其基础),那么恶意程序或者一些特殊的代码模式可以精确地“炮制”冲突。
想象一个攻击场景:一个攻击者可以构造一个循环,其中包含两个或多个分支,它们的 PC 对 BTB 大小取模后,会映射到同一个索引。例如,在一个 512 条目的 BTB 中,地址 A 和 A + 512 会竞争同一个槽位。
如果使用顺序替换:当分支 A 进入 BTB 后,它占用了索引 I。过一段时间后,分支 A + 512 进入,由于顺序替换,它会覆盖索引 I 上的条目。
攻击者可以通过精确控制分支的执行顺序,“挤掉”处理器中正在使用的重要分支预测(例如,一个频繁执行的关键循环的预测),从而显著降低分支预测的准确率,引发大量的分支 mis-prediction(分支预测错误)。这相当于一次针对处理器性能的** denial-of-service (DoS) 攻击**。
因此BTB 越大,就不会产生 BTB 别名冲突,也就不会覆盖掉宝贵的分支历史信息。
我在 nemu 上,用 C 语言模拟了 biriscv_npc,基本信息是:
1 | |
下面是我的结论:
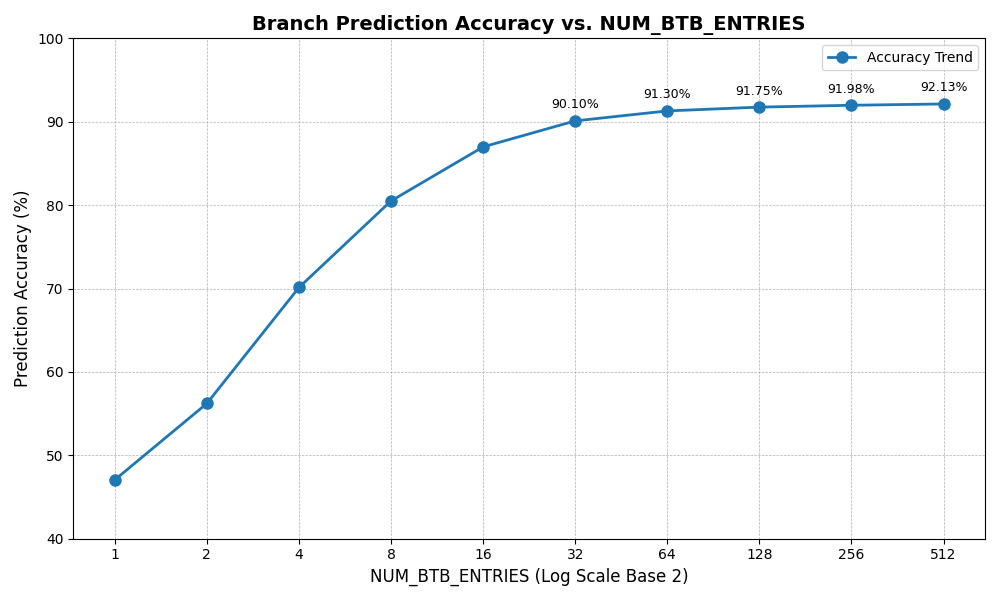
可以看到,在 NUM_BTB_ENTRIES 达到 32 之后,正确率增长就很缓慢了。
BHT 容量
1 | |
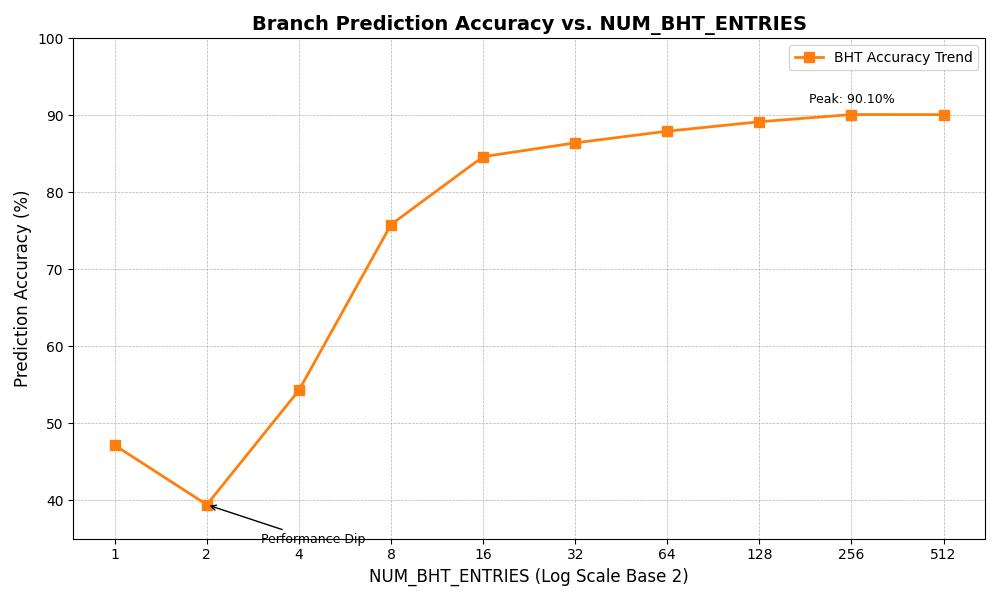
可以看到,在 NUM_BHT_ENTRIES 达到 256 之后,几乎不增长了。
分析
对于 BTB 而言,替换策略的关键之处是不能替换掉那些最近被使用的项,考虑到时间局域性,这被替换掉的项可能马上就会遇到,从而降低预测正确率。
因此一个非常简单的策略就是循环计数,策略就是从 0、1、2、3… 最后对 NUM_BTB_ENTRIES 求余数,大致如下:
1 | |
但是前面提到,这会导致针对处理器性能的** denial-of-service (DoS) 攻击**。因此,要让攻击者无法预测,就得找到一个随机的最长序列,循环周期最好是 0~NUM_BTB_ENTRIES-1,这样既无法预测,也不会影响性能。
大致长这个样子(思考为什么要避免掉 0):
1 | |
因此一个关键的数就是 LFSR_TAP。LFSR_TAP 对于能找到周期为 NUM_BTB_ENTRIES-1 的伪随机序列很关键,对于一个具体的 lfsr 生成器而言,找到一个 LFSR_TAP 是有特定求解步骤的。
现代的分支预测器不仅仅是简单地存“分支目标地址”。它们还包含复杂的逻辑,如:
- 分支方向预测:预测这个分支是_taken(跳转)还是not-taken(不跳转)。
- 共享分支预测器:记录不同分支之间的历史行为模式。
- 间接跳转预测:预测函数调用的目标地址。
一个顺序的访问模式可能会在这些“高阶”预测器中留下可被利用的痕迹。例如,一个固定的访问模式可能会让预测器误以为某些分支之间有关联,而实际上没有。LFSR 的伪随机访问模式可以更好地“打散”这些访问,使得每个 BTB 条目的访问都更接近独立事件,从而避免训练预测器去学习一个虚假的“模式”。
为什么随机?(伪随机 vs. 真随机)
我们之前一直在说 LFSR 能生成“乱序”序列,但更准确的说法是它能生成“伪随机”序列。为什么我们不直接用一个硬件的“真随机数发生器(TRNG)”呢?
事实上,对于 BTB 探测我们需要的是“伪随机”,而不是“真随机”,考虑以下原因:
- 性能是第一位的:BTB 是处理器流水线中访问最频繁的单元之一,其延迟直接决定了处理器的时钟频率。LFSR 的极低硬件开销和极低延迟是任何 TRNG 都无法比拟的。
- 可复现性对调试至关重要:当分支预测出现问题时,工程师需要能够精确复现这个场景。使用 LFSR,只要设置好初始值,每次仿真或运行都能得到完全相同的探测序列,这使得问题定位和调试变得非常容易。如果用 TRNG,每次结果都不同,调试将是一场噩梦。
- “足够随机”即可:我们的目标不是生成无法破解的密码,而是破坏攻击者或编译器生成的代码的规律性。LFSR 生成的序列已经具有非常好的统计特性和“不可预测性”,足以实现这个目标。一个懂硬件的攻击者可以分析出 LFSR 的多项式和初始状态,从而预测出序列,但这比预测一个简单的顺序计数器要困难得多,而且已经超出了普通程序优化的范畴。
GShare 预测器
GShare(Global History Sharing)预测器的强大之处在于它巧妙地结合了两个信息源:程序计数器PC 和 全局历史寄存器,来共同决定访问哪一个 BHT 分支历史条目。
GShare 的核心思想
在直接映射的分支历史表中(BHT),一个非常严重的问题是冲突(Conflict)。两个不同的分支指令 PC_A 和 PC_B 可能会计算出相同的索引,从而总是相互“干扰”对方的预测历史。PC_A 的行为可能会覆盖掉 PC_B 的历史,导致预测准确率下降。
GShare 的解决方案是:
- 不再仅依赖
PC来计算索引。 - 而是将
PC和分支的全局历史记录(Global History Register, GHR)进行异或(XOR)操作,用这个结果作为索引。
全局历史寄存器 是一个移位寄存器,它记录了最近所有分支指令的跳转/不跳转结果(1 表示 taken,0 表示 not-taken)。例如,如果最近有 4 个分支,其结果分别是 [1, 0, 1, 1],那么 GHR 的值就是 1011。
这样做的好处是:
即使两个 PC 冲突了,如果它们在全局历史中的行为模式不同(例如,一个分支倾向于在特定历史下跳转,另一个则不倾向),它们通过 XOR 之后的索引也不同,就不会互相干扰了。这相当于给每个 PC 都配备了一个“历史感知”的哈希函数。
学习过程
“学习”这个行为体现在 bht_update 函数中。当一条分支指令执行完毕,我们知道了它的实际结果(taken 参数),此时需要:
- 找到对应的 BHT 条目。
- 用实际结果更新这个条目的状态。
- 更新全局历史寄存器。
1. 寻找 BHT 条目(索引计算)
1 | |
2. 更新 BHT 条目(饱和计数器)
1 | |
3. 更新全局历史寄存器
1 | |
我们将本次分支的经验记录了下来,让它成为未来预测的一部分。GHR 是一个有“记忆”的寄存器,它记录了过去的“教训”。
通过这个过程,GShare 预测器不仅记住了单个分支的倾向性,还学会了分支之间的相关性和模式,从而大大提高了预测的准确率,尤其是在处理复杂的循环和函数调用时。
验证规律的 lsfr 对 GShare 的影响
1 | |
无规律的 lsfr: 89.174844%,有规律的 lsfr: 89.092477%。
可以看到,有规律的 lsfr 对准确率确实带来了负面影响,因为 GShare 就是在学习访问 BTB 的行为之间的关联,如果很有关联,那么 GShare 就会记录下来,从而学习到错误的模式。